java传统IO流-BIO
介绍
数据都以二进制存储在设备中,流就是将这些数据以二进制在各种设备间进行传输。
IO流的核心特点:
- 顺序读写:读写数据时,大部分情况下都是按照顺序读写,读取时从文件开头的第一个字节到最后一个字节,写出时也是也如此(RandomAccessFile 可以实现随机读写)。
- 读写数据时本质上都是对字节数组做读取和写出操作,即使是字符流,也是在字节流基础上转化为一个个字符,所以字节数组是 IO 流读写数据的本质。
分类
流根据数据的流向不同分为:输入流和输出流。
- 输入流:从磁盘或者其它外设中将数据输入到进程中。
- 输出流:从进程中将数据输出到磁盘或者其他外设中保存。
字符流&字节流
根据处理数据的基本单位不同分为:字节流和字符流。
- 字节流:以字节(1Byte=8bit) 为单位做数据的传输。
- 字符流:以字符为单位做数据的传输。
字符流的本质也是通过字节流读取,Java 中的字符采用 Unicode 标准,在读取和输出的过程中,通过以字符为单位,查找对应的码表将字节转换为对应的字符。
根据这两种分类,在java.io包中定义了四个顶层的抽象:
| 数据类型/数据流向 | 字节流 | 字符流 |
|---|---|---|
| 输入流 | InputStream | Reader |
| 输出流 | OutputStream | Writer |
在这四个顶层抽象下面还有很多的成员,分别有不同的作用。
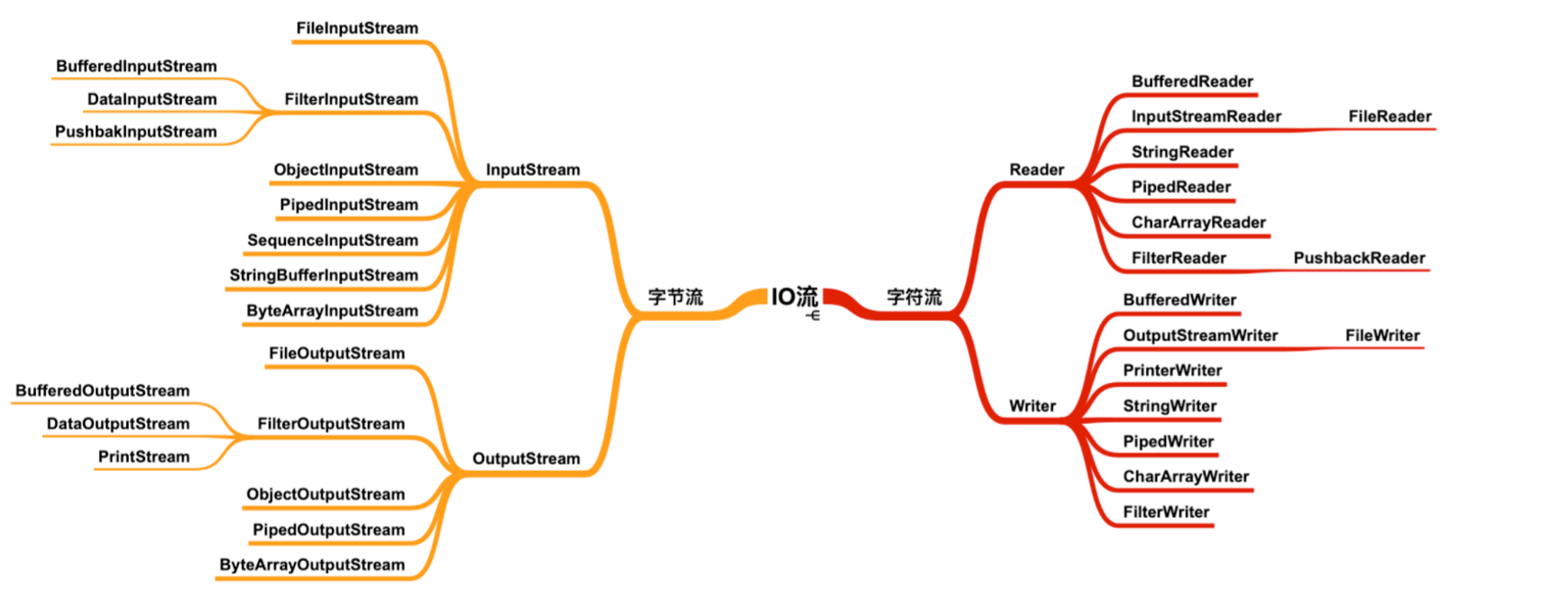
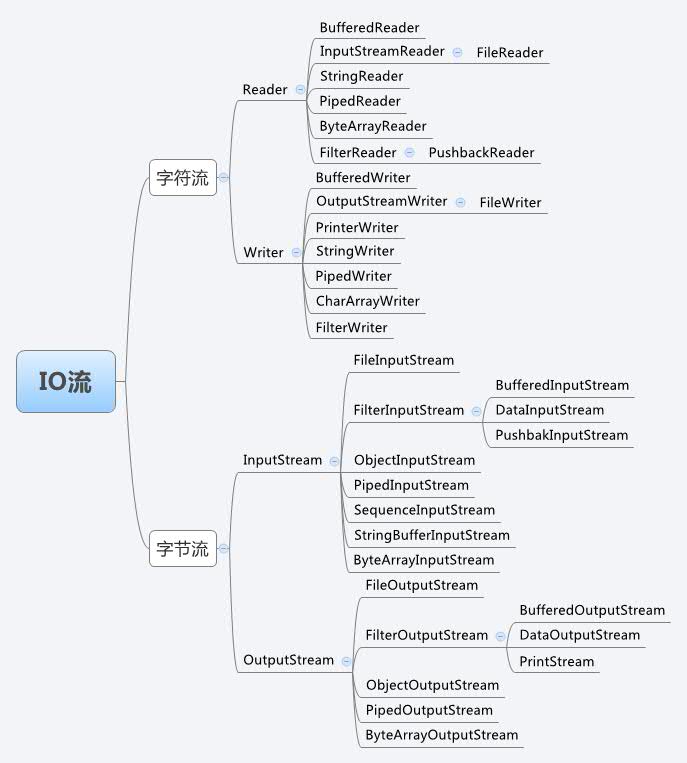
java中处理传输用的外,还提供了一堆扩展的流,比如压缩,序列化用的。
这其中还提供了用于字节流与字符流中间的转换流。
| 转换流/数据类型 | 转换 |
|---|---|
| 输入(字节->字符) | InputStreamReader |
| 输出(字符->字节) | OutputStreamWriter |
在存储设备上,所有数据都是以字节为单位存储的,所以输入到内存时必定是以字节为单位输入,输出到存储设备时必须是以字节为单位输出,字节流才是计算机最根本的存储方式,而字符流是在字节流的基础上对数据进行转换,输出字符,但每个字符依旧是以字节为单位存储的。
节点流和处理流
这是对流的根据功能的再一次分类。
- 节点流:节点流是真正传输数据的流对象,用于向特定的一个地方(节点)读写数据,称为节点流。
- 处理流:处理流是对节点流的封装,使用外层的处理流读写数据,本质上是利用节点流的功能,外层的处理流可以提供额外的功能。处理流的基类都是以Filter开头。
还有将两个流合并的SequenceInputOutStream。
字节流和字符流的转换
从任何地方把数据读入到内存都是先以字节流形式读取,即使是使用字符流去读取数据,依然成立,因为数据永远是以字节的形式存在于互联网和硬件设备中,字符流是通过字符集的映射,才能够将字节转换为字符。
java中提供了两种转换流:
- InputStreamReader:从字节流转换为字符流,将字节数据转换为字符数据读入到内存。
- OutputStreamWriter:从字符流转换为字节流,将字符数据转换为字节数据写出到指定位置。
- 传统的 BIO 是以流为基本单位处理数据的,想象成水流,一点点地传输字节数据,IO 流传输的过程永远是以字节形式传输。
- 字节流和字符流的区别在于操作的数据单位不相同,字符流是通过将字节数据通过字符集映射成对应的字符,字符流本质上也是字节流。
整理
所有的流基本如下:
| 数据类型 | 基于字节的Input | 基于字节的Output | 基于字符的Input | 基于字符的Output |
|---|---|---|---|---|
| 基础 | InputStream | OutputStream | Reader | Writer |
| 转换 | InputStreamReader | OutputStreamWriter | ||
| 数组 | ByteArrayInputStream | ByteArrayOutputStream | CharArrayReader | CharArrayWriter |
| 文件 | FileInputStream、RandomAccessFile | FileOutputStream、RandomAccessFile | FileReader | FileWriter |
| 管道 | PipedInputStream | PipedOutputStream | PipedReader | PipedWriter |
| 缓冲 | BufferedInputStream | BufferedOutputStream | BufferedReader | BufferedWriter |
| 过滤 | FilterInputStream | FilterOutputStream | FilterReader | FilterWriter |
| 解析 | PushbackInputStream、StreamTokenizer | PushbackReader、LineNumberReader | ||
| 字符串 | StringReader | StringWriter | ||
| 数据 | DataInputStream | DataOutputStream | ||
| 数据格式化 | PrintStream | PrintWriter | ||
| 对象 | ObjectInputStream | ObjectOutputStream | ||
| 合并流 | SequenceInputStream |
传统BIO的问题
- 每个请求都需要创建独立的线程,与对应的客户端进行数据处理。
- 当并发数大时,需要创建大量线程来处理连接,系统资源占用较大。
- 连接建立后,如果当前线程暂时没有数据可读,则当前线程会一直阻塞在Read操作上,造成线程资源浪费。
参考文献 & 鸣谢
相关文章